

I don’t have anything against plays, per se. I’m just as excited for Harry Potter and the Cursed Child as the next millennial who grew up staring out their window at night, waiting for their letter from Hogwarts, only to get screwed over by what can only be assumed was an incompetent owl delivery service. There’s just something about the magic of the books that seems untouchable — irreplicable.
That being said, in honor of the upcoming play, I’m going to try to recreate a bit of that magic.
Language models are a fundamental aspect of natural language processing (NLP) that attempt to learn a probability distribution over sequences of words, such that — given a history of previous text — they can generate new sentences, one word at a time, completely from scratch. In the real world, they’re used in everything from speech recognition to information retrieval; in our world, they’re going to help us rewrite Harry Potter.
The next section is going to give a brief layman’s overview of the magic behind the neural nets, LSTM’s, and word embeddings that make up our language model, and after that we’ll jump right into The Good Stuff.
Deep learning for language modeling
I’m going to try to keep these explanations as high-level and non-technical as possible, so anyone already familiar with (or uninterested in) the theory can feel free to just skip this section.
Machine learning powers a good 90% of the technological miracles you see and hear around you each day, including self-driving cars, Siri, credit card fraud detection, Amazon and Netflix’s recommendation engines, and, as of recently, even Google search itself. Of course, just about 100% of these systems include a lot more than just machine learning, but we’ll get into that later.
At its core, the most powerful of these “artificially intelligent” systems boils down to something called a neural network, an algorithm originally designed to mimic the human brain: input signals, neurons that react to these signals, and outputs that carry the information to other neurons.
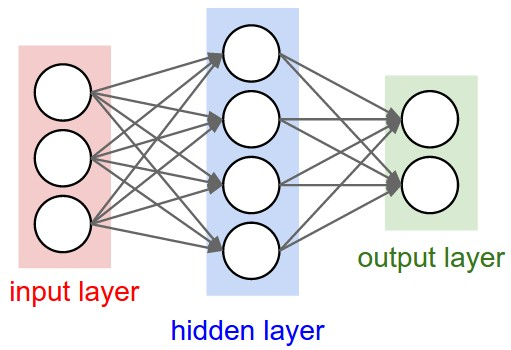 A vanilla neural net. Source.
A vanilla neural net. Source.
In computer science, this translates to a set of input values, one or more hidden layers to hold intermediate calculations, an output layer, and a series of weights connecting each neuron from one layer to the next. These weights, which are “learned” from data by the computer (the process of which I won’t get into, but is essentially a glorified version of guess and check + calculus), are supposed to capture the importance of each neuron with respect to outputting the correct decision in the end. Deep learning, which has been getting all the hype recently with being the “future of AI”, really just consists of different variants of the basic neural net with multiple hidden layers.
Yes, I know. Deep literally means deep — lots of hidden layers. That’s it. We can both go build our own self-driving cars now.
As powerful as the basic neural net model is, there are a number of significant limitations. For example, it can only work with inputs and outputs of a fixed length. However, a vast number of tasks can’t be expressed with those constraints. Take machine translation for example — how are we supposed to take variable-length input and output sentences in two different languages and cram them into a regular neural network?
The answer: we don’t. That’s where RNN’s come in.
RNN’s, or recurrent neural networks, were designed to address this exact shortcoming. At their most fundamental level, RNN’s model sequences: a series of images, sounds, words, etc., where (1) the order in which each element in the series appears matters, and (2) the same calculation is performed on each element.
As a result, RNN’s look exactly like a regular neural network, except with a self-contained “loop” in the hidden layer that repeats the calculation for each element.
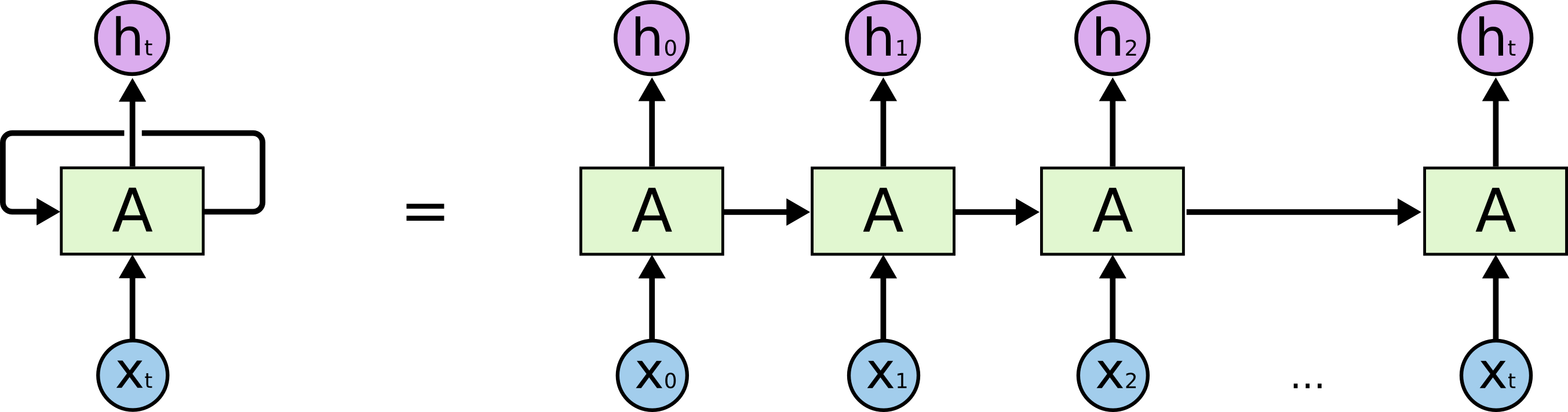 Recurrent neural network, unfolded through time (right). Source.
Recurrent neural network, unfolded through time (right). Source.
The calculation for the neuron at each time step not only considers the immediate inputs and the weights, but also the history of the past inputs and calculations, in order to determine the next logical step. (If you’re interested, check out these MIT scientists that trained a model to predict human behavior by binge-watching The Big Bang Theory and The Office. And you think you’re bored after work.)
With RNN’s, which can be “unfolded” through time to pass calculations through each iteration of the hidden layer(s), we can finally begin building our language model. What I actually ended up using was an LSTM (long short-term memory) RNN, a variant on the basic RNN model that addresses some of its fundamental shortcomings in dealing with long sequences (e.g. vanishing and exploding gradients). I’m not going to go in depth on them here, but colah’s blog post on them is absolutely fantastic. In essence, each unit is further regulated by a series of “input,” “forget,” and “update” gates that allow the network to control information flow.
Word embeddings
Before getting into some of the fun text the Harry Potter language model generated, I want to talk briefly about one of the more interesting parts about the project: word embeddings.
The idea is simple. Take a sentence we want to feed into our model: “Harry got out of bed.” In order for the machine to process it as an input, each word needs to be encoded into some sort of unique, numerical equivalent. A naive approach would be to simply count off all the words in the source vocabulary one by one, i.e. “Harry” = 1, “got” = 2, etc. However, as you can imagine, this leaves out a lot of syntactical information about the words and the relationships among them. With this approach, “Harry” would be just as distinct from “Ron” as “Harry” is to “fly.”
The solution? Embed each word into a learned, high-dimensional vector space, where words that are close in meaning are similarly close in the vector space. In other words, train the computer to computationally comprehend the meaning of words.
These embeddings are also learned by a neural net, using either a CBOW (continuous bag-of-words) or skip-gram architecture, and either way they give us some pretty amazing results. For example, even a rudimentary one is able to capture the semantics of gender relationships and pluralities:
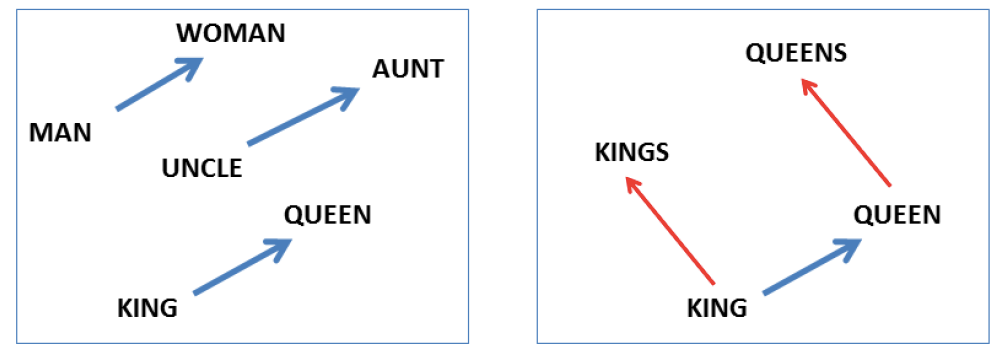 Word embeddings in the vector space as visualized in a low-dimensional space. Source.
Word embeddings in the vector space as visualized in a low-dimensional space. Source.
In the following language model, each word of the seven Harry Potter novels was transformed into a high-dimensional embedding that was learned in parallel with the parameters — or weights — during training.
The Good Stuff
If you skipped the previous section (or, more likely, started reading it and got bored), here’s where you start reading again.
There were a couple properties of this particular piece of text that made it particularly difficult to learn from:
-
Hagrid’s style of dialogue added a whole other layer of complexity for the model, which can be seen getting confused at times.
-
The original writing contained a lot of stuttering, all-caps yelling, dialogue interruption, etc. that likely threw off a lot of rules the algorithm was trying to learn from the rest of the text.
-
Preprocessing for the text was not exactly thorough (which was admittedly my fault), and as a result there were quite a few character-level errors that may have also thrown the model off.
That being said, I’ll start by showing off a couple sample passages the computer generated. Please don’t try too hard to understand them — they’re pretty hilariously awful:
He looked around, his room sprang to Hermione’s huge eyes.
“You are here? Is it near here?” she asked.
“Nothing,” said Ron, beaming at him.
“The Dark Lord wishes one thing,” Dumbledore looked incredulously at Harry, who was looking wildly around on his face in his mind. “We were all safer around this carriage, and we can’t go home a start and pretty brave in my study. They would have proved to let them.”
“We’ve got to see you — and if we can go and get out of here when you’re going a good brother!” Harry began, but he made a horrible, mechanical figure from a sweatshirt from all his head; and then turned again. The Knight Bus’s bewilderment was negotiating by the stares Harry had run into his pocket at her sons when he saw Professor Lupin together after Winky called out of the bird of Quirrell’s glum, tone more as though he walked through the trees in a sort of shimmering laughter.
“You will be able to recall foreign toilet?” said Snape eagerly.
… and …
Slughorn had disappeared too. She raised her eyebrows.
“Don’t you, Ron, he’s here?” asked Harry.
“Yeah . . . well . . . nothing than we go, I trust,” said Harry, looking positively embarrassed. “They have had a sign of cleaning gnomes, four penalties above you … I won’t make you want her! Let me search for a level and make it safe, and concentrate on a Decree for their bodies, and Dumbledore and I can make an antidote look — ”
Harry raised his fist and down the desks.
“Ten minutes?” said Harry. She was on her feet, “were my name!”
“Got here the way you’re okay,” said Hermione flatly.
“What?” Harry called back for a moment.
The wizard flickered out of the corner and opened her leg and dabbed at the crowd because Harry had gone.
“In the wrong morning, Runcorn?” snapped Harry nervously.
So…yeah. Like I said, J. K. Rowling isn’t being replaced anytime soon.
That being said, especially in light of the added difficulties I mentioned above, there are a couple things the model did very well:
(+) It picked up on Rowling’s general writing style (without being able to actually write, of course). Distribution of sentence lengths, paragraph lengths, dialogue structures, entities, and even the way dialogue tends to be introduced and closed (“said Hermione flatly,” or “asked Harry nervously”) have all been properly replicated.
(+) It (sort of) learned grammar. In particular, sentences — while oftentimes semantically ridiculous — are generally pretty close to being syntactically correct, e.g. wrong word choice but correct part of speech.
(+) Word embeddings captured some semantics and long-sequence sentiments. In particular, check out this generated passage:
Dumbledore turned around upon the cold, sallow face that Harry had just a table.
“Chuck his stuff like Tonks,” Muriel told a hoarse voice.
“Oh, come on,” said Mrs. Weasley. “Only two weeks ago!” The chill was on all fours, Harry didn’t feel they would simply have to take his hat.
“Winky did for you to crash, Harry,” said the witch in a shaking voice. “I got yeh’ if he got to.”
“All of you, anyway,” said Madam Pomfrey grimly, though a late, invisible bottle and a prickling, like her bushy black head that looked curious.
“ Er — please!” said Mrs. Weasley.
“ And I’ m going on,” says Skeeter hoarsely, her voice barely very pink with great dislike.
Notice the general sentiment and tone behind the passage, and notice the words that contribute to it. “Cold, sallow face,” “hoarse voice,” “chill”, “shaking voice,” “grimly,” “great dislike,” — all pretty ominous, right? In other words, the machine has learned to interpret and sustain a certain tone of words, at least to a certain extent.
On the other hand, of course, the model has a number of glaring failures:
(-) Most of it doesn’t make any sense. Shrug
(-) The model has no recognizable long-term memory. That is to say, even when the sentences make sense, they don’t come together to form a story. While RNN’s are theoretically able to build on sequences of any length (although this particular model was capped at an input length of fifty words), even the LSTM variant can’t capture enough long-term sense to build “events” in a coherent manner.
(-) The model does not understand pronouns and antecedents. There are a lot of “self-referencing” issues, such as:
He, Ron, and Hermione looked stricken at Hermione, as he moved forward.
“You go,” she sighed.
“Harry hasn’t got a word,” said Harry. “This is what. . . carried away from her! Why would they be?”
So what?
 Wrong fandom, I know. Source.
Wrong fandom, I know. Source.
Long story short: automatic text generation is hard.
Aside from getting to generate some pretty hilariously nonsensical text in the style of famous authors (when trained on Shakespeare, for example, the same model had Lord Willoughby referring to Lucentio as “sir, my gentle ass”), this project serves as a good case-study for some fundamental barriers in modern AI. I’ll hopefully get around to them in a later post, but in the meantime, here’s the code for this project, which you can use to go replicate an infinite amount of unintelligible Harry Potter text at your leisure.
Many thanks to sherjilozair and Andrej Karpathy’s original blog post on the subject for inspiration. Happy coding, and all hail J. K. Rowling.